

4 min read
4 min read
Making smart business decisions is dependent on a company's ability to use its data effectively.
Internal company data has a lot to offer. However, in a world of complex connections and a fast-growing ocean of accessible data, it is naïve to think that useful and competitive information can be harvested without benefiting from external data sources. As more and more data becomes available, businesses are developing a new way of thinking.
Every piece of the puzzle is needed in order to see the big picture
Matching external sources to internal data becomes an entity resolution and data linkage question, and it's one that businesses in every industry are struggling to answer. At ThinkData, we help companies discover, govern, and monetize the data that powers their business.
For example, one of our banking clients is interested in ingesting new streams of import/export data that we provide on Namara. By linking external import/export data to their internal client data, the bank will be able to uncover new client trade activities that were otherwise unknown, identify true wallet size, investigate trade trends, monitor growth, map clients, and ultimately gain insight into a previously opaque part of their business. Every one of these advantages is dependent on linking the bank's internal client data to the external data feed provided by ThinkData.

Source: Unsplash
UK companies data on Namara
To link this valuable export/import data feed to the bank's internal client data, a third external data source is needed. This third data feed is an extremely useful public repository of all businesses in the UK which can be linked to external trade data feeds. This connection provides us with the key to connect to the bank's internal data. This data set was harvested and organized by ThinkData.
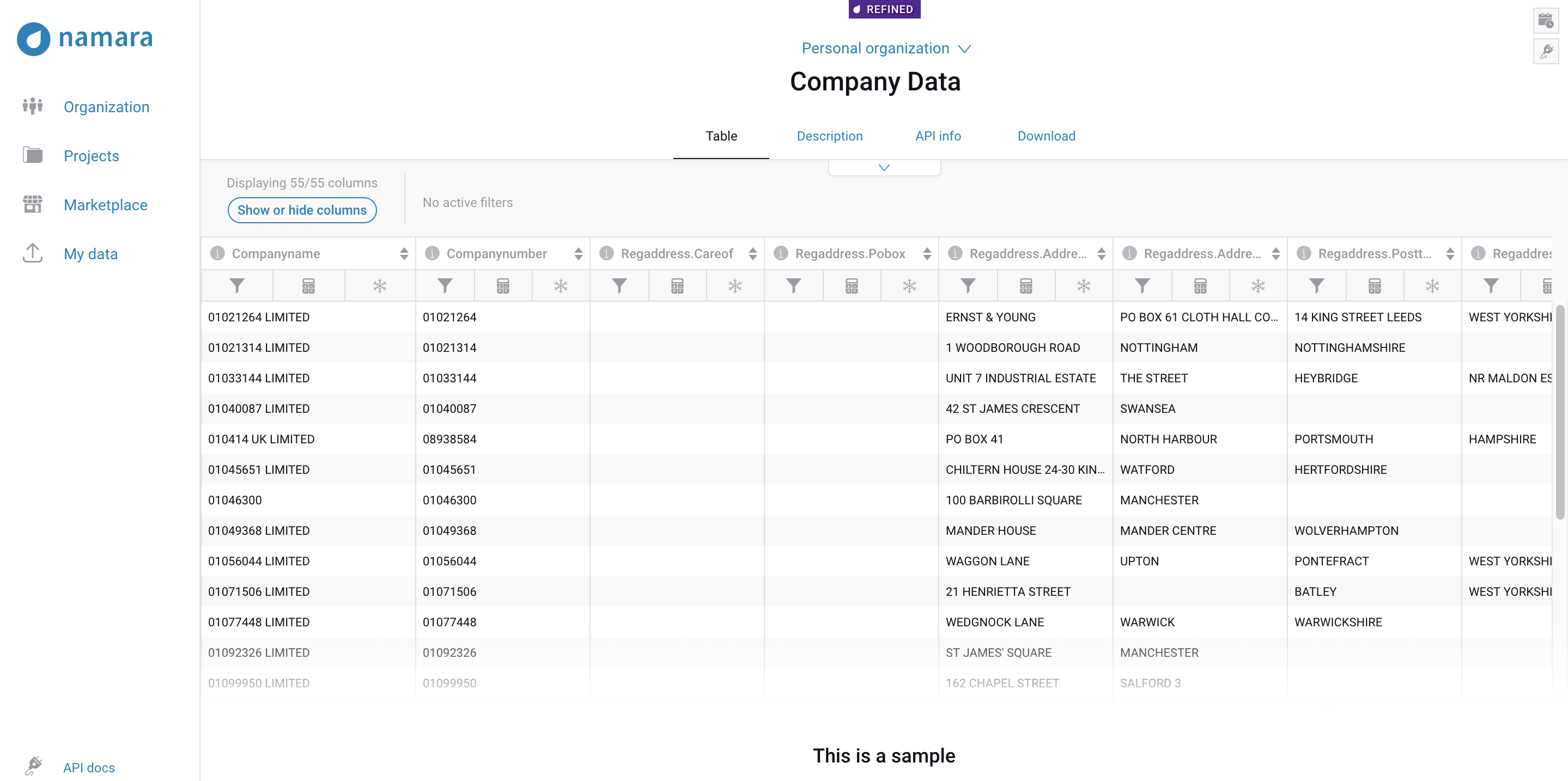
Sample of company data being gathered and organized by the Namara Platform
The UK companies data set has about 4 million rows of company registration information in 55 columns including basic information such as company names and addresses. Since some of the companies appear in more than one row with similar information, the data set needs to be deduplicated. After omitting the repetitive information, we can then assign a unique ID to each company in this data set, which can be used later in connecting to the import/export data.
Global exports data feed
Let's consider a scenario in which we want to use the export data feed, filter it on UK based companies, and connect this data to the UK companies information on Namara. First, let's take a look at this data set. A sample of this data feed contains various trade information in 20 columns, such as:
- Date
- Exporter information (name, id, address)
- Consignee information (name, id, address)
- Information on exported goods (weight, quantity, value, etc.)
- Etc.
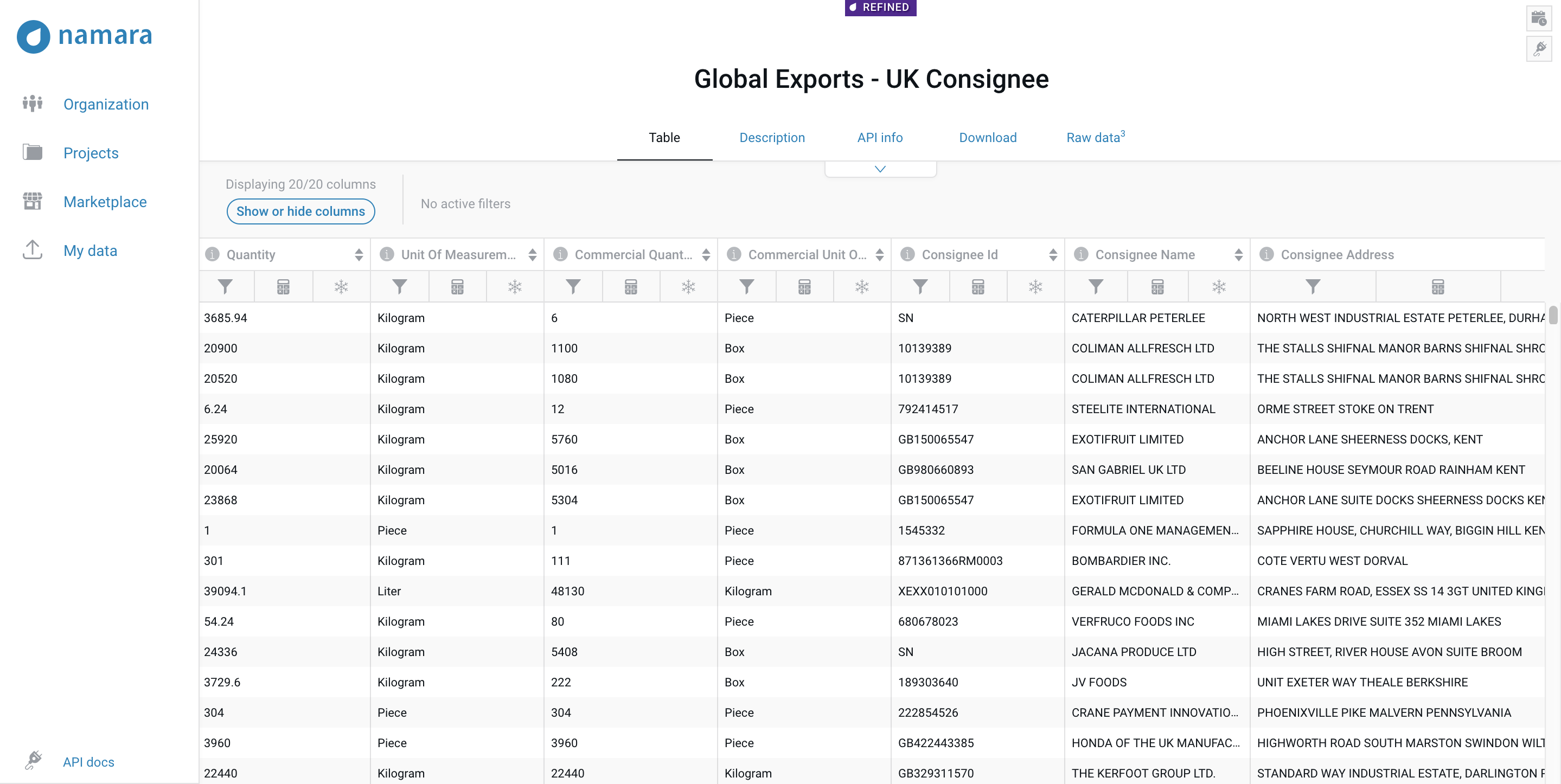
Sample of global exports data being filtered and connected to the UK companies information on Namara
Note that not all of the columns are populated for every record. This plays an important role in choosing the columns we want to use for the matching exercise.
Results: Connecting global export data to UK companies data
Since both the global export data and UK companies data are missing information in some columns, we decided to use the company name field in the UK companies data. Additionally, we used the consignee name (representing UK companies involved in the deal) field in the export data feed to make the connection.
Since these two columns are always populated in both data sets, the first attempt in connecting these data sets was based on matching these unstructured text fields.
An unstructured text field could contain anything and is not necessarily cleanly recorded company names.
The first step is performing the required pre-processing steps to make these data sets ready for the matching pipeline. We designed and performed a fuzzy matching algorithm which includes the following steps:
- An indexing algorithm is used to extract a good subset of similar fields. This helps with the performance of the algorithm and saves time by choosing pairs from two data sets that are more likely to be a match.
- The candidate pairs are then processed by the text-matching algorithm. Our approach breaks down the names and takes into account many different scenarios in which a specific name can appear. This algorithm computes a score of match for each record in the global export data set to its closest match in the UK companies data.
- The generated scores reflect the probability of the match which then is used to extract the most likely matches.
- The final result would be the global export data set with an extra column which has the unique ID of corresponding company in the UK companies data set.
The following image shows 20 randomly selected records with the corresponding match score. We can see that the score appropriately reflects the level of confidence in match, and the matching algorithm has a good tolerance for small typos and variations.
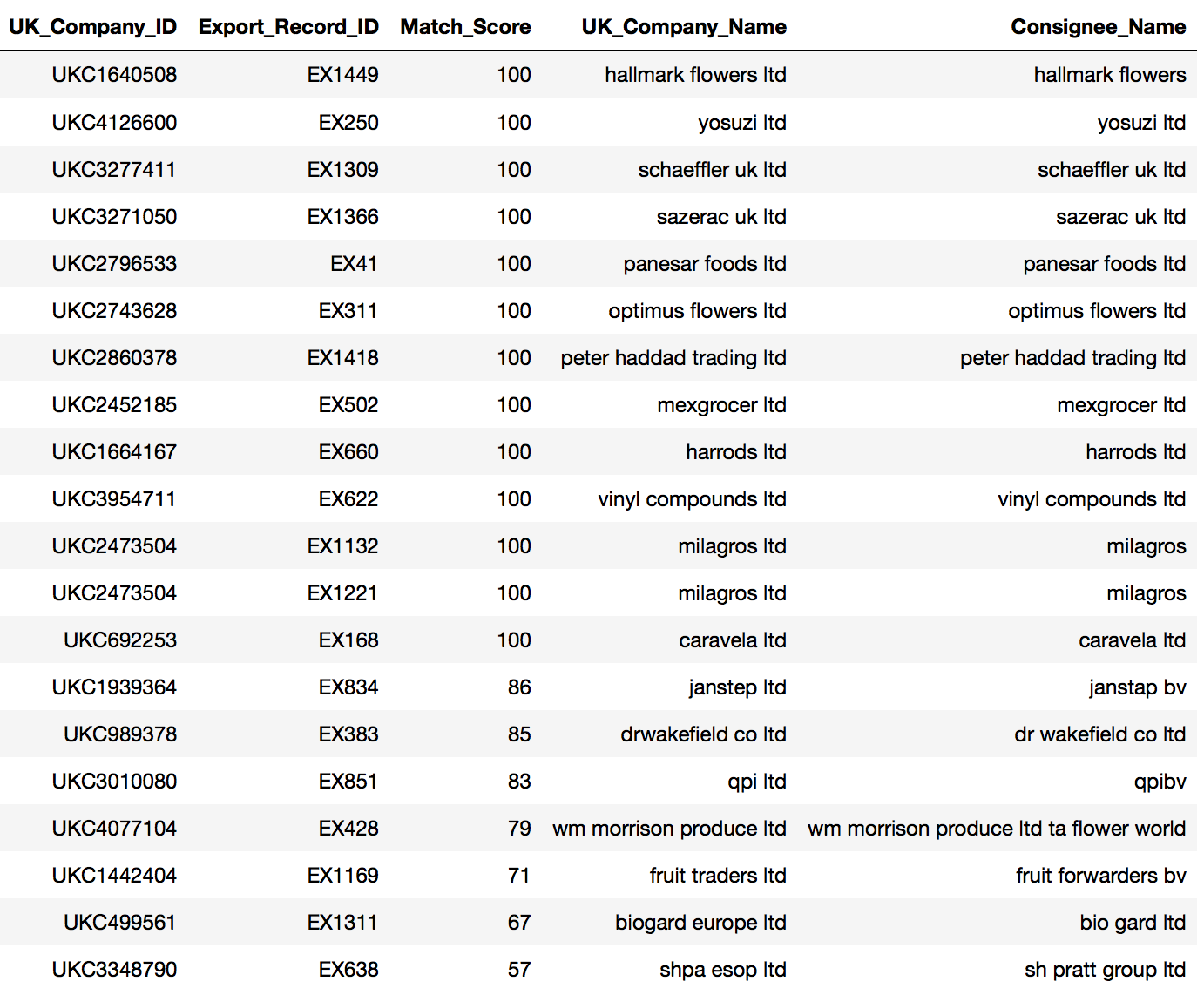
Based on this ID, the two data sets are then linked and ingested to Namara. The resulting data set can then be used by the banking client to merge this information with their own internal client data.
This process adds new transaction level data to the bank's internal data, providing them with competitive and valuable information on their current and prospective clients; information that was not available before linking to external trade and company data sets on Namara. It helps them understand not only who's linked to trade and where they are, but what they're importing/exporting, and how much.
Map of UK Exporters Companies House created on Namara
Data-Driven Value
For modern companies, data is the key to unlocking major opportunities, better understanding your market, and developing advanced analytics. As we move toward AI and ML-driven tech, the quality of insights will be reflected in the quality of the data that is being used. By enriching internal company data with external feeds of data, fast-moving businesses are establishing a pipeline that can deliver actionable information on demand which gives them the time and resources needed to grow their business.
Want to learn more about data enrichment?
Request a consultation with one of our data experts to talk about our data services and how ThinkData’s tech can advance your projects. If you're interested in learning more, read how MaRS Discovery District applied entity resolution to Ontario Businesses.

4 min read
How to better leverage data for risk management and crisis response
It’s becoming increasingly difficult to manage risk in a global climate that’s growing in complexity. On the other side of this coin, however, is an...
3 min read