

4 min read
We’ve been talking a lot about our products because there has been some incredible progress on what we’re delivering to the organizations we work with. From tip to tail, we’re changing the way users on the Namara platform access, enrich, manage, and monitor the data flowing through their environment.
But what’s the underlying stuff? At a high level, what is external data and why is it so valuable?
What is external data?
The way we see it, it’s not as easy to pin down as most assume. It seems like anything created outside your organization would count as external data, right? But there’s a problem with that.
The problem is, you don’t use data as an organization – individuals or distinct business units within that organization use the data. Meaning, unless your company has perfect standards across the board, the way one person or department structures data won’t be exactly the same as another. There’s a vast spectrum of differences in the way people and machines record labels, addresses, business names, dates, descriptions, and anything else you might find in a dataset.
So if somebody looked at two datasets from two different departments from the same company, would they think they were generated by the same person and same method? If not, that second dataset has to be treated like external data; it doesn’t follow the same conventions, structures, and rules that the original dataset does. There’s work to be done to get the two to function harmoniously.

The farther you get from home-grown data, the less control you have and the greater the opportunity for variability.
Taking all that into account, we at ThinkData say that any data created outside of your four walls is external (although, we came up with that before most people were working from home, so you’ll have to grant us a bit of leeway on that). If it doesn’t follow the exact same standards and methods laid out by a direct mandate, it is external data.
The call external data is coming from inside the house
Tying together an organization's data ecosystem is crucial to becoming data-driven, and for aligning your data strategies with your business strategies. It’s also the data that’s most predictable for your team, and, with a coordinated effort, it can be completely under the control of the company itself. Furthermore, by being able to analyze all the data under your own roof, you get the benefit of better process standards, deeper knowledge of your customer/client base, and hopefully a basis for connecting your whole team around data.
Knowing where to start isn’t easy. In fact, we’ve got a primer on the subject of conducting a data audit within your company, and it’s a process with a lot of moving pieces – you won’t hear us say otherwise. But it’s critical to establish a baseline: it sets a precedent for new data; it reveals where there are gaps and overlaps in your data strategy; and it enforces getting mechanisms in place to see the use and movement of data between every department within your organization. Powerful stuff.
Open, public, and premium data
Even if you haven’t fully solved the puzzle that is “internal external” data, there is an entire universe of data available to anybody who wants it. What's more, there are far better ways of getting it than using your highly-skilled team to set up and manage individual scripts for data gathering, not to mention the prep that goes into loading it into your system and transforming it to meet your required schema – all required steps before you can even start using it.
Governments, NGOs, private enterprise, and special interest groups release tremendous amounts of data daily. That data requires prep, cleansing, and transformation, but as the saying goes, “there’s gold in them thar hills!” We’ve known that since day one of ThinkData Works. Our specialty is connecting our users to any data from any source. We handle the heavy lifting so that your data teams produce better insights faster.
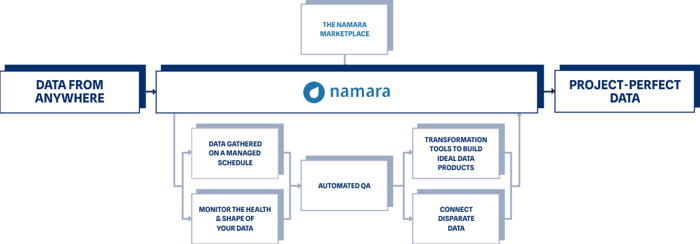
As we initially established, these third-party providers are sources of external data, and even though it may not be specific to your own internal data, it’s as or more valuable.
Being mindful of data tunnel vision
Without getting into the semantics of known-unknowns, unknown-knowns, and so on, there is a significant risk to using data that’s too focused, segmented, or specific. Analyzing this kind of data produces skewed results, and it’s easy to get stuck with only your “known-knowns.” It's important to know these things, but it's only a small corner of the whole picture.
When COVID-19 hit, companies everywhere had to take a long, hard look at their supply chains to see where the weak links were, then try to pivot and adapt to maintain business continuity. Without a picture of the entire ecosystem, it was impossible to understand what else is out there. External data offers insights not just about where shortcomings are, but where opportunities lie.
If the only thing your organization is looking at is what’s in your immediate scope, you’ll never be able to get truly predictive because you’ll never see the wider market shifts that are happening constantly.
Why external data means richer insights
On the flip side of the argument above, tapping into broader signals will widen and enhance your insights, even when comparing against more granular data. By looking at the information ecosystem as a whole, analysts and data scientists are able to see more than outcomes – they’re able to find trends and causes for shifts, gains, losses, and changes. This deeper, broader knowledge allows organizations to get predictive and unlocks a competitive advantage.
Let's draw an example: we need the true value of a house. We can look at the historical sold price, but that might be years out of date. We can multiply that price by inflation and a national housing price increase factor to get something a little closer, but not perfect. Certainly, any renovations to the house and grounds should be accounted for. But do these things alone give us a clear picture or a rough guess?
Now, let's start layering in external data:
- crime statistics in the region will tell you about the area;
- demographics may indicate more houses in this area will be up for sale in less than 5 years;
- building permits within a small radius give you a sense of how the neighbourhood is changing;
- historical weather patterns give a picture of the viability of solar panels, if renewable energy sources are a factor;
- new home developments in the area are indicators for growth in population and businesses in the next 10 years; and
- business insolvencies in the region can tell you if the area is thriving or in decline.
This is far more complete, even though it's not information about that specific house. It's also all data that can be leveraged immediately if you've figured out a scalable way to get this external data into your ecosystem. If you haven't, you'll be limited to your known-knowns, and will be immediately outstripped by someone who can move faster and deliver better, fulsome insights.
Taking a ground-up approach to external data
If you want to get serious about bringing in external data, start the right way. Have a scalable method for bringing new data assets in, find reliable partners and data marketplaces to discover new sources, and ensure your entire organization has a way to collaborate and rally around a single source of truth for data, even if different departments use it for different purposes.
Centralizing teams around data assets is critical for success – becoming data-driven means your business revolves around the data, not the other way around.
Want to learn more about aligning your business and data strategy?
Request a consultation with one of our data experts or browse the largest catalog of solution ready data to determine how ThinkData’s tech can advance your projects.

4 min read
How to better leverage data for risk management and crisis response
It’s becoming increasingly difficult to manage risk in a global climate that’s growing in complexity. On the other side of this coin, however, is an...
3 min read