

4 min read
90% of the data in existence has been generated in the last two years. On a daily basis, 7.5 sextillion gigabytes of data are generated – around 147,000 gigabytes per person. These numbers are staggering, but it’s to be expected: the world is growing and the machine economy is growing exponentially.
That's not to say that all of this data is immediately useful. Organizations can’t simply tap into these sources without massive amounts of pre-processing – but is anybody putting in the work? Forrester reported that within enterprise companies, 73% of data still goes unused for analytics. There’s still a major gap between business strategies and data strategies – your organization's predictive solutions will only be as sturdy as the initial problem statement. Organizations need to establish specific use cases, according to Gartner, and deploy technology with measurable outcomes to realize the value of AI.
Data is a big piece of the puzzle
The metaphor is still around – data is the new oil (although, with the phrase having been coined in 2006 at the latest, maybe it’s not so ‘new’). It’s definitely valuable in a raw state. It’s even more valuable when it’s refined. But when it is turned into a product, purpose-built to solve a specific problem, its applications are innumerable and its value skyrockets.
The same holds true for data: organizations need to remember that the ultimate goal here isn’t to collect as much data as possible. They need to extract the value from data and apply it to a specific business problem. The idea of observing data, learning from it, and then automating work based on that feedback is at the heart of machine learning.

Despite what's often portrayed in Hollywood, ML is not moving toward proving the "Terminator Hypothesis."
Understanding machine learning
Before any organization can become data driven, it’s important to understand the basics. People often think that the end goal of machine learning is graphs and visualizations on data displayed on a live dashboard. ML is about automating tasks (not about replacing jobs) and it’s more than just putting stats on display. Broadly, machine learning teaches computers something about the world, so that machines can use that knowledge to perform other tasks. Statistics, on the other hand, teach people something about the world, so that they can see a bigger picture and make informed decisions.
Companies that are strategically scaling AI report nearly three times the return on AI investments compared to companies pursuing siloed proof of concepts, according to Accenture. Clearly, ML is not some dolled-up dashboard; in fact, it can help your organization build intelligent systems that can imitate, extend, and augment human intelligence to achieve certain “machine intelligence,” allowing the people in your organization to focus on solving problems better suited to humans.
However, the majority of organizations are struggling to implement scalable AI solutions, and are missing out on the benefits (see: money). The problem? Your organization doesn’t have a talent shortage, but a strategy shortage. Not convinced? Let’s look at some numbers.
Solutions that scale
Since 2015, there’s been a 344% growth in data science job demand. We can clearly see that organizations are investing in growing their data science teams with the impression that if they continue to hire data scientists, innovation and digital transformation is an automatic by-product. However, only 27% of enterprise data is used, and factoring in external data is even more shocking – out of all the data available in the world, less than 1% is being used in analysis.
There is a tipping point for all of this data. Companies can sink millions into building gigantic data teams to scour the Internet finding and prepping data from all over – but this will never be a scalable solution, and it’s the absence of a management strategy that’s causing a bottleneck.
What do companies need to deploy AI and ML?
So where does the process begin, and how do organizations actually build and deploy successful machine learning projects?
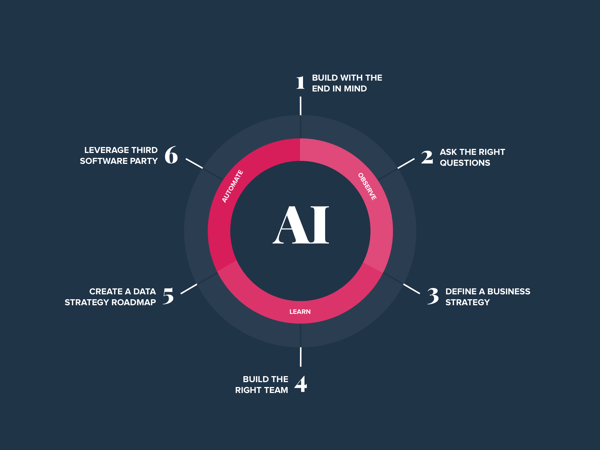
-
Start with the end in mind. You have to clearly understand the problem you’re faced with and the solution that you’d like to achieve. In bowling, you can knock down ten pins with every ball, but it’s only a perfect game if you’re throwing down the right lane. With ML, you need to know what you're aiming at. Organizations are goal-oriented, they are always looking to increase revenues and boost KPIs – if your problem doesn’t address these goals, it may be off-target.
- Ask the right questions. The majority of businesses aren’t asking the right questions ahead of attempting to solve a problem with ML. Analyze and understand what you can and can not answer, then figure out how your predictive system can actually benefit the end user. A key question to ask: “Is my project going to be deeply driven by the value it can create for the organization?”
- Define a business strategy. The same care and detail for strategizing must be implemented with data and ML projects that you would apply to any other project. You need specific, measurable, and achievable goals, an implementation plan, and metrics that help track the success of the project. It’s not enough to simply look at your project from a technical level, you need to be able to connect the solution to your organization. For example, after implementing your model, will your company have increased revenue or attained a solid competitive edge in the market?
- Build the right team. Organizations fail to hire the right candidates for the job often because they either don’t know what they’re looking to achieve or have a conflicting perception of the role of a data scientist. A data team is made up of more roles than just the data scientists, and it would be ignorant to think that one role is able to build and maintain warehouses, architect data workflows, write perfectly optimized machine learning algorithms, and run analysis on everything. To fill the right roles for the project, you need to clearly define your objectives, understand the nuances of each technical role/team structure, and ensure that all of this is outlined in your recruitment postings. The chart below shows the relative importance of core skills for the emerging roles in data science:

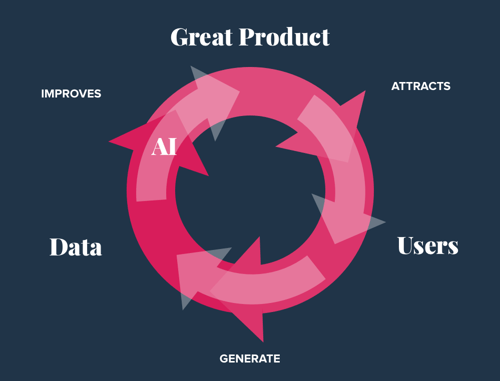
- Create a data strategy roadmap. Data is the key asset for ML projects as it trains the models. According to Andrew Ng, a pioneer in the field of Artificial Intelligence, the biggest and most successful products have the most users. Having the most users usually means you get the most data, and with modern ML, having the most data often means you can create the best AI. The above concept is described in the diagram below:
- Leverage third-party software. Don’t try to reinvent the wheel and build an in-house data pipeline. In order to successfully launch AI, it’s important to select the right tools that can help your organization with the tasks that can be automated in sourcing, scraping, standardizing, refining, and integrating data. The Dimensional Research report conducted on behalf of Alegion found that ultimately, 71% of teams outsource training data and other machine learning project activities. In the ‘build vs. buy’ debate, the companies who choose ‘build’ spend more time and money. Remember, you’re not hiring data janitors, you’re hiring data scientists. Adopting DataOps tools and finding ways to automate the prep and process phases of the data lifecycle will lead to shorter time to insight.
It's never easy – but it doesn't have to be so hard
Some businesses don’t have enough data, others are struggling with more than a decade's worth that's unusable. Having data does not automatically mean insights can be drawn from it. Organizations are failing to recognize the required prep work that is needed to extract insights from data, so more and more bottlenecks show up when it comes to innovation and growth. It’s not the absence of data, it’s the absence of usable data.
Data is a big factor in creating predictive and intelligent solutions, but there’s more to data than just having a lot of it. Find a problem, find the right people to solve it, and give them the tools they need to solve it effectively and to measure their efficacy – these are the requirements for successful ML.
Want to learn more about aligning your business and data strategy?
Request a consultation with one of our data experts or browse the largest catalog of solution ready data to determine how ThinkData’s tech can advance your projects.

4 min read
How to better leverage data for risk management and crisis response
It’s becoming increasingly difficult to manage risk in a global climate that’s growing in complexity. On the other side of this coin, however, is an...
3 min read