

4 min read
4 min read
I recently saw a Facebook post that captured the perfect sunset with a not-so-perfect caption that read "as dust fell" instead of "as dusk fell." Often when I'm browsing Facebook, I'll read something that doesn't seem quite right. When a phrase has correct words substituted for similar-sounding ones that, more often than not, don't make sense, it's called an eggcorn.
The term was coined in 2003 by linguist Mark Liberman after hearing a story about how a woman mistakenly referred to "acorns" as "eggcorns." Since there was no specific word for this erroneous phrase, eggcorn was chosen in the same metonymic tradition as "mondegreen." This makes the term eggcorn an eggcorn itself!
Eggcorns qualify as such by replicating some sense of the original sound of the word or phrase:
- All intensive purposes (all intents and purposes)
- At your beckon call (at your beck and call)
- This day in age (this day and age)
- A goal-getter (a go-getter)
- It takes two to tangle (it takes two to tango)
Scrambled egg(corns)
Recently, we wanted to investigate a unique use case for our entity resolution capabilities and found this absolute trainwreck of a paragraph:
I hole-hardedly agree, but allow me to play doubles advocate here for a moment. For all intensive purposes I think you are wrong. In an age where false morals are a diamond dozen, true virtues are a blessing in the skies. We often put our false morality on a petal stool like a bunch of pre-Madonnas, but you all seem to be taking something very valuable for granite. So I ask of you to mustard up all the strength you can because it is a doggy dog world out there...
It goes on like that for a while, and it doesn't get any less painful.
How can we deal with this mess?
Our goal is to find a way to correct all the eggcorns in this paragraph. For a bit of background, entity resolution (often referred to as fuzzy matching) is the process of identifying and resolving multiple occurrences of a single entity to reveal a clearer picture of the information within the data, even when there are differences in the way these entities are recorded.
In order to match the paragraph, we needed a dataset to connect. Conveniently, we have a dataset already hosted on Namara that contains mappings of incorrect idioms and eggcorns to their correct counterparts.
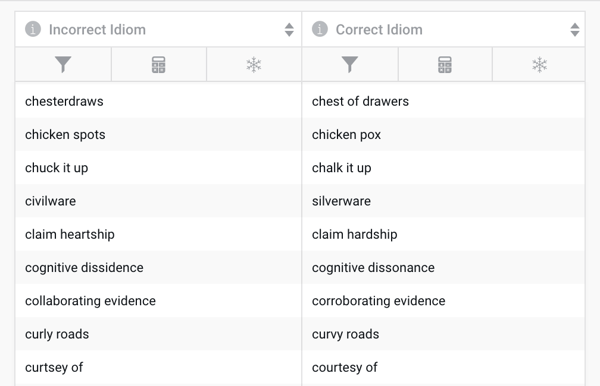
Now, we want to correct all the issues found in our original paragraph using our entity resolution system and this Idiom Map dataset. Since our entity resolution was designed to work with datasets, it's going to require a bit of extra code to work with sentences. For now, let’s just focus on the first 3 sentences.
- I hole-hardedly agree, but allow me to play doubles advocate here for a moment.
- For all intensive purposes I think you are wrong.
- In an age where false morals are a diamond dozen, true virtues are a blessing in the skies
I count 5 eggcorns; a good sample for experimentation.
Our strategy is to create a sliding window across each sentence to compare groups of 4 words to entries in the idiom map for correction. We use groups of four words here because that is the maximum length of an incorrect eggcorn according to our dataset. After normalization, this sliding window looks like this:
- i hole hardedly agree
- hole hardedly agree but
- hardedly agree but allow
- agree but allow me...
For each window in each sentence, we can run entity resolution to compare that fragment to the dataset of incorrect idioms. If a match is found, we can simply replace it with the correct idiom. Let’s see how this works for the first three sentences:
- i whole heartedly agree but allow me to play devils advocate here for a moment.
- for all intents and purposes i think you are wrong.
- in an age where false morals are a dime a dozen true virtues are a blessing in disguise.
This works!
Resolving entities
Let’s apply our de-eggcorning script to the entire paragraph and see the results (note that all punctuation was removed during the normalization step).
I whole heartedly agree but allow me to play devils advocate here for a moment. For all intents and purposes I think you are wrong. In an age where false morals are a dime a dozen true virtues are a blessing in disguise. We often put our false morality on a pedestal like a bunch of prima donnas but you all seem to be taking something very valuable for granted. So I ask of you to muster up all the strength you can because it is a dog eat dog world out there...
There you have it, fixing incorrect phrases in a paragraph using entity resolution in about 50 lines of code. You can find the entire script here.
The business case for entity resolution
It was entertaining, but our phones aren't ringing off the hook because we can resolve bad idioms. Let’s go through a more traditional example of business name resolution.
As an example, there are two databases storing business names with slightly different formats. Duplicates exist between the two databases, but they are never exact matches. The two databases need to be deduplicated and joined together in an effort to develop a master data management system. After extraction and data cleansing, the data looks like this:
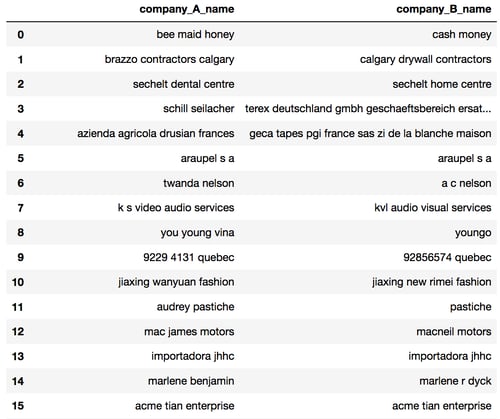
Using our tools, merging these two datasets is simple. We describe where the datasets are located and which columns we want to link between them. Computationally, this is expensive: the first dataset contains 16,562 entries and the second one contains 46,209. Since the algorithm for entity resolution grows at a quadratic scale, and we are performing 627712 comparisons, that's nearly 4 billion operations! Despite this, our system is still able to complete this task within 17 seconds through the use of distributed computing (using Apache Spark). The resulting output looks like this:
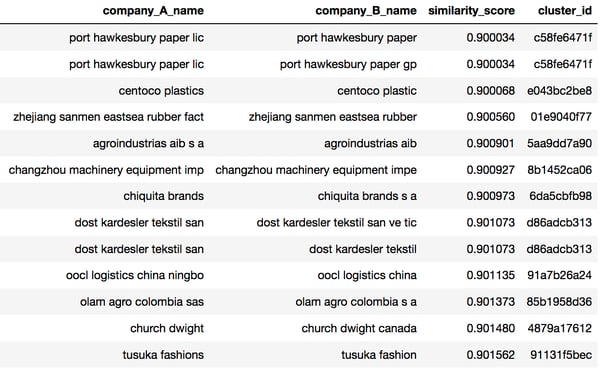
There’s tremendous value in data, but the key to learning from data is in connecting it. However, the task of connecting data isn’t simple and it’s extremely time consuming (despite how effortless the two above examples look). Our entity resolution capabilities provide data professionals with an automated solution that creates links between data points that lead to deeper insight. The less time data scientists spend mired in prep and processing, the more time they can spend on actual data science – it’s a win-win for any organization.
Want to learn more about data enrichment?
Request a consultation with one of our data experts to talk about our data services and how ThinkData’s tech can advance your projects. If you're interested in learning more, read how MaRS Discovery District applied entity resolution to Ontario Businesses

4 min read
How to better leverage data for risk management and crisis response
It’s becoming increasingly difficult to manage risk in a global climate that’s growing in complexity. On the other side of this coin, however, is an...
3 min read