

4 min read
5 min read
We’ve written a lot about finding and preparing data lately. But that’s only the beginning when it comes to extracting value from it. When organizations begin flowing external data through their organization, the various issues associated with data sharing start causing problems. Some of these issues include:
- Controlling permissions and data access, including sharing partial/filtered views or picture-in-picture data
- Accurately tracking changes to data and monitoring how that affects the performance of models, even (and especially) when the data updates regularly
- The ability to open up and share the data with other people and/or organizations that may benefit from it
Working with up-to-date data is important. However, reproducibility in data science gets complicated when datasets update regularly, and scaling while using a specific point-in-time instance of a dataset is a problem.
For example, somebody may use a dataset to build a machine learning model, achieve their desired degree of accuracy, then test it thoroughly and be happy with the results. But if the data updates later, the performance of their model may drop sharply. With the old data now gone, the model has to be updated to adapt. This can be annoying, time-consuming, and even embarrassing (“It was working fine yesterday...”).
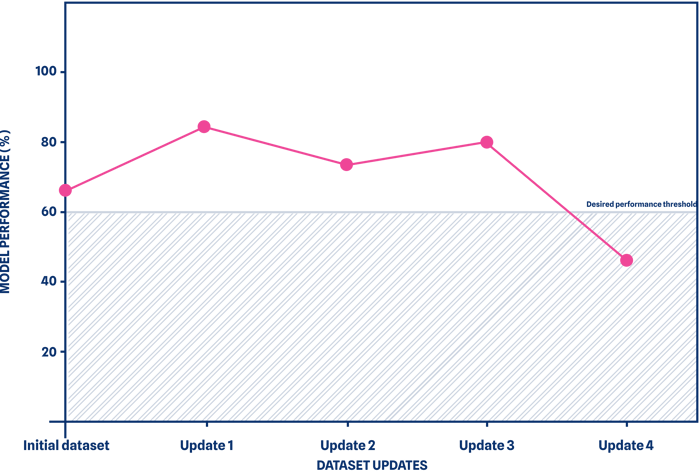
User can select ‘Update 3’ to maintain an acceptable model performance instead of being defaulted to the latest revision (Update 4).
At ThinkData we are data people first and foremost, and we understand these frustrations because we've lived them, too. One day things are fine, then the dataset updates and everything’s off. In a closed system, using static data, this doesn't happen. But introducing data with any kind of variety or velocity (how it's structured and how it updates) into a model, app, or system exposes you to these kinds of problems.
Before we explain how we solve the problem, we need to explain what the problem is a little better. Data scientists know this all too well, but if you're not a data professional it might come as a surprise to know that dataset updates aren’t all the same. Revisions can be made to a dataset in the form of a change, addition, or replacement to the previous values in the data.
Imagine a dataset that adds a new row every week. Over the course of the year there will be 52 revisions to the dataset as it grows over time, but there may also be additional revisions to previous values as the source data gets updated ("initial data said there were 42 new infections on March 17th, but newer data suggests the number was closer to 48"). Revisions are a concept used to track dataset changes where the values change but the schema stays the same (i.e. rows of data being added or removed). Versions, however, are a concept used to track schema changes (i.e. columns being added, changed, or removed). So if in the previous example, the source suddenly starts tracking recovery rates in addition to infection rates, the dataset properties will change, creating a new version.
Data tracing with Tracked Revisions
To create a solution for data science reproducibility, we built revision tracking into the Namara platform. In other words, if there are changes to the rows in a dataset, a new revision is made for that dataset. Users can use 'tags' to identify, query, and keep track of these revisions. You’re no longer restricted to using only the most recent revision of a dataset. Users can flow back and forth in time to take advantage of the dataset they need until they’re ready to work with the latest changes.
Key Benefits of Tracked Revisions:
- Reproducibility: ability to create scalable solutions built on stable data
- Flexibility: users can use revisions that persist by using tags, and manually deprecate revisions
- Time to adapt: never be caught off-guard by updating data – use a working revision until you can bring your models, analyses, and dashboards up to date
- Auditing and traceability: it's not enough enough to say that "at one point" the data looked a certain way. In order to maintain data governance, it is critical to be able to refer to a point-in-time snapshot of how the data looked on the day it was modelled or used.
Data from anywhere through one lens - External Tables
The potential in external data to enhance solutions is endless. Finding valuable data from alternative sources isn’t difficult; it’s using that data within your organization that takes work (see how to get data into your organization with an ETL or data prep tool).
The Namara platform is built to reduce the overhead when it comes to using more data within your organization. Our users can import data into a private instance of Namara through either a drag-and-drop interface or, for more power and control, directly from their own data warehouses. We've written elsewhere about the work we've done to make our Ingest pipeline capable of managing data variety on the fly.
But for organizations that want to stream data directly without using an external ETL, we wanted to make it simple to use Namara to see and query data that exists anywhere. To make it easy to pull in big data quickly, we built external tables to integrate with a wide variety of data science environments. External tables allow users to link directly to their own warehouses and query the data without majorly retooling any processes.
External data without External Tables:
External data with External Tables:
Key benefits of external tables:
- Blank canvas: agnostic way to use external data in Namara
- Less friction: reduced overhead in ingesting external data compared to other data science tools
- Hyper-secure data residency: absolute certainty that private or sensitive data stays where it should with the freedom to query it directly
Data collaboration and sharing - RBAC
Data sharing and collaboration are key aspects of creating diverse solutions. But it can’t be a simple on/off switch – organizations need granular control over how data is used and shared.
We realized the importance of sharing permissions and a fine-tuned strategy for data privacy. Accordingly, we evolved our permissions model to a role-based access control (RBAC) system. Within Namara, members of groups and organizations can be assigned roles so that managers and administrators can choose who is responsible for what. Users can be assigned to manage members, view all datasets, edit datasets, manage groups, and import datasets, or any combination of the above.
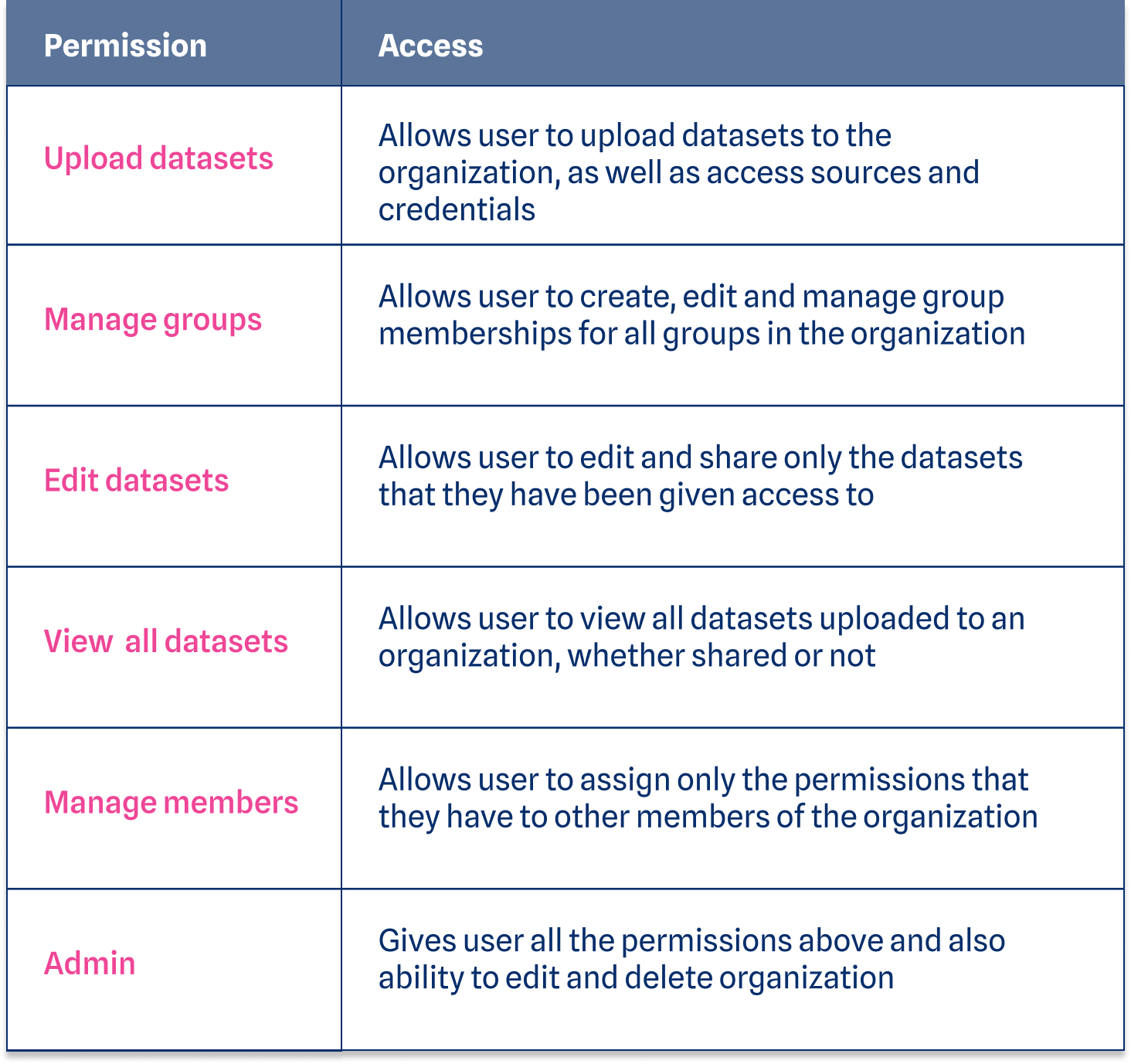
Each permission can be assigned independently to suit the individual privileges each user needs. With this change, a user can be added to an organization, or even just a group within that organization, and get only the access they need.
Key Benefits of defined permissions:
- Data governance: users can be given access as required, ensuring that they’re locked out of features that they don’t need/shouldn’t have
- Clearly defined: it’s simple to understand what access is given with any role and even simpler to assign them
- Increased transparency: easier than ever to audit access and understand the flow of data through an organization
Adding flexibility to your Data Operations
Increasingly, data teams need to leverage external data and collaborate. It seems like what's needed is contradictory: better overall access but with increased data governance and somehow maintaining reproducibility.
The Namara platform is designed to help organizations use more data with more confidence and less overhead, and that means giving our users a way to model their organizational structure, control the flow of data, and use any data like it’s their own.
We work with data every day. We want to make connecting to different data from different sources easy, because that's where the best insight comes from. As the need for data governance and auditing grows, we will continue building tools and features that let users trust the data they depend on.
Want to learn more about aligning your business and data strategy?
Request a consultation with one of our data experts or browse the largest catalog of solution ready data to determine how ThinkData’s tech can advance your projects.

4 min read
How to better leverage data for risk management and crisis response
It’s becoming increasingly difficult to manage risk in a global climate that’s growing in complexity. On the other side of this coin, however, is an...
3 min read