

4 min read
4 min read
How does Spotify win against a competitor like Apple? They use data better. Using machine learning and AI, Spotify creates value for their users by providing a more personalized and bespoke experience. Let’s take a quick look at the layers of aggregate information that are used to enhance their platform:
- Spotify uses natural language processing (NLP) to scan discussion forums about the music you’re listening to, then matches your preferences to other music being discussed similarly. This provides additional dimensionality to the classification system.
- The composition of the music is analyzed for tone, sound, loudness, major or minor key, and several other factors used to recommend similar songs and artists.
- Finally, Spotify measures behaviour when listening to music, tracking repeat plays, or skipping past a song. These behavioural metrics help in establishing preferences and therefore improve the recommendations to the user.
The core data here is in the music – the basic components of songs like the title, artist, and duration. Choosing a song to listen to sets the baseline (and maybe you like it for its bass line). Everything else can be seen as metadata: additional elements about how one listens, how the song is composed, and what other music it sounds like.
Metadata, here, is the driving force of Spotify’s algorithm, and it’s collected and applied constantly to provide you with intelligent recommendations to keep you listening.
What is metadata?
In simple terms, within the technology industry, “meta” refers to an underlying definition or description. More directly, metadata provides context about the data, more than what you see in the rows and columns.
That definition is quite broad, but that’s mostly because it can be used for almost any purpose – it can tell you what each column header means in detail, who uploaded the data and when, the column and row counts for the whole dataset, the original data source, or even warehousing and residency requirements.
Breaking down metadata
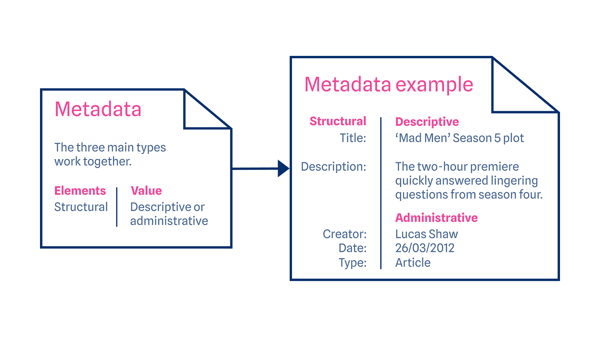
There are 3 main types of metadata that work together: administrative, descriptive, and structural. Each serves a different purpose in explaining the corresponding data.
Structural metadata – provides insight regarding how data elements are organized. This facilitates quick and easy navigation, like a table of contents or page numbers. Structural metadata allows similar data to be grouped together, documenting relationships among different data.
Administrative metadata – offers technical information about the data. It covers aspects such as the origin of the data, type of data and access or usage licences.
Descriptive metadata – adds information about the owner, when the data was created/published, and what the data includes. The essential purpose is to ease identification and offer a snapshot of the data it describes.
A combination of these types of metadata allows organizations to navigate through vast amounts of data efficiently, making it easy to find what you need when you need it.
Why is metadata important?
51% of analytics consumers have difficulty locating and accessing data content. With increasing amounts of data, it is important for organizations to understand the data they have, where it is, and how to use it.
Metadata's utility does not begin and end with describing data. Metadata can enable easier data discovery, and can help increase understanding of a dataset. Take a library book, for example. If the text is the primary data, the book jacket may have a brief summary of the book, and comments from others about the book. Importantly, the library may also append data that gives the book a category, genre, and unique identifier for easier organization and retrieval.
Metadata can also assist in compliance with regulatory requirements by ensuring that your organization tracks usage, sharing, and licence permissions at the dataset level. By appending metadata that makes it clear how the data can be used, for what purpose, and who it can or can’t be shared with, you’re able to build security and compliance into the data itself.
Metadata management through a data catalog solution
By managing your metadata, you're effectively creating an encyclopedia of your data assets. Metadata management is a subset of data management, which itself falls into the category of data governance.
The primary reasons to focus on metadata management, then, are the same reasons for implementing data governance strategies: improving data security, data quality, and overall transparency.

Improving data security:
- Ties usage restrictions, data licensing directly to data
- Includes data ownership, maintainer
- Consolidates and codifies information associated with a dataset so it can’t be lost
Improving data quality:
- Designing/implementing ontology
- Data linkage made easier
- Insight into changes to the over time
Improving transparency:
- Increases discoverability
- Creates records of usage, access, and updates
- Shares information without revealing sensitive data
Instead of treating metadata as additional attributes, files, and pieces of information that exist outside the data, metadata management is about linking this rich information to the dataset itself in a way that’s easy to access, enforce, and manage.
Getting more with a metadata-enabled catalog
Using ThinkData’s specific tools and features, you can unlock valuable benefits stemming from metadata:
Custom metadata – the ability to add any metadata to a dataset, including linking datasets, upload use agreements, licensing, and data dictionaries
Configurable property definitions – the data catalog lets you input schema descriptions within the dataset, tying metadata to the properties
Dataset versioning/revisions – versions of each dataset structure as the schema changes over time, and tracked revisions each time the data is updated. This way, users can track stable versions of the data while updating their models and dashboards
Dataspec – a dashboard for reports and alert configuration based on the data as it changes over time, including ‘macro’ information (like row and column counts) or ‘micro’ information (like value types or value bounds)
Access Auditing – specific usage statistics and information which describe user behaviours, API calls, and other access-based actions.
Flexible management, strict governance
Metadata management falls under the branch data governance – one of the most crucial parts of an effective data strategy. We know that every organization has unique needs, and a good metadata solution should be strong and enforceable, but flexible enough to manage data in a way that’s tailored to each company.
By offering comprehensive metadata management, ThinkData enables our clients to build data-driven solutions on strong, secure foundations.
Do you think your business has a need for a data catalog to find, understand, and use trusted data to drive business outcomes? Reach out to start using better data and using data better.

4 min read
How to better leverage data for risk management and crisis response
It’s becoming increasingly difficult to manage risk in a global climate that’s growing in complexity. On the other side of this coin, however, is an...
3 min read