

4 min read
Increasingly, companies are focused on finding ways to connect to new and valuable sources of data in order to enhance their analytical capabilities, support data governance initiatives, and deliver more insight to their business units.
Due to the increased demand for new data sources, companies are also looking at their internal data differently. Organizations that have access to valuable datasets are starting to explore opportunities that will let them share and monetize their data outside the four walls of their business.
The data sharing landscape today
Data sharing has become top of mind for organizations reassessing their data strategy. The ability to distribute data effectively - both within an ecosystem and to external parties - represents a new and exciting value proposition. Data “monetization” (the strategy of extracting more value from data you own, whether by reselling it or using it more broadly within your organization) is becoming prominent because it represents the elusive return on investment that data divisions have historically struggled with. Recently, Venturebeat featured data sharing specifically as part of their 2021 Machine Learning, AI, and Data Landscape, and highlighted a few key developments in the sphere:
Google launched Analytics Hub in May 2021 as a platform for combining datasets and sharing data, dashboards, and machine learning models. Google also launched Datashare, developed more for financial services and based on Analytics Hub.
Databricks announced Delta Sharing on the same day as Google's release. Delta Sharing is an open source protocol for secure data sharing across organizations.
In June 2021, Snowflake opened broad access to its data marketplace, coupled with secure data sharing capabilities.
As an organization founded on the collection and dissemination of public data, ThinkData Works has always made data sharing a cornerstone of our technology, and recently, our capacity to securely share data within and outside of an organization has increased through cloud native data virtualization tooling, which enables hub-and-spoke data sharing while maintaining data residency.
The changing needs for modern companies
There are some things to consider when it comes to sharing data. Choosing who you will let use your data, and for what purposes, is an important question that organizations should think through from both a strategic and governance perspective. But outside of the rules about who will use your data and why there are also logistical problems involved with sharing data that are more technological than legal in nature.
When it comes to data – whether it’s coming in or going out, public or private, part of core processes or a small piece of an experimental model – how you connect to it is often as important as why. For modern companies looking to get more out of their data, choosing to deploy a data catalog shouldn’t mean you have to move your data. The benefits of a platform that lets you organize, discover, share, and monetize your data can’t come at the cost of migrating your database to the public cloud. For organizations that have relationships with several cloud providers, cloud native solutions provide a mechanism to deploy on preferred architecture while still gathering data from anywhere. Once it’s in a catalog, however, what’s the best way to push it out?
The value of finding and using new data is clear, but the process by which organizations should share and receive data is not.
Memory sticks aren’t going to cut it, so what does a good sharing solution look like?
Owner-defined access
Often, when organizations want to share the data they have, they have to slice and dice the datasets to remove sensitive information or create customer-facing copies of the dataset. Aside from the overhead of building a client-friendly version of your datasets, this is bad practice from a data governance perspective.
Making and distributing a copy of a dataset creates a new way for data and data handling to go wrong every time, and opens up possibilities for inconsistencies, errors, and security issues. If you want to share the dataset to ten different people for ten different use cases, you’re repeating work and multiplying risk every time you do.
A good data sharing solution lets data owners create row- and column-level permissions on datasets, creating customized views of one master file, ensuring all data shares still roll up to a single source of truth. This concept of federated ownership and rule-based enforcement stands directly in opposition to the previous rule of IT ownership and enforcement. Done correctly, they are equally secure, and this new model opens up opportunities for value extraction that the previous one does not.
Consistent and configurable metadata
Most datasets aren’t built to be consumer-facing. If the data is generated as a by-product of a core business process, it’s probably particular to a very specific use case that may not be shared by the end user who wants to use the data.
Metadata is the key that lets us understand and use data effectively. Whether it’s descriptive, telling us who created the data and how we should interpret it, or administrative, declaring who owns it and how it can be used, managing and maintaining quality metadata is the most efficient way to ensure anyone understands how to use the data they have access to.
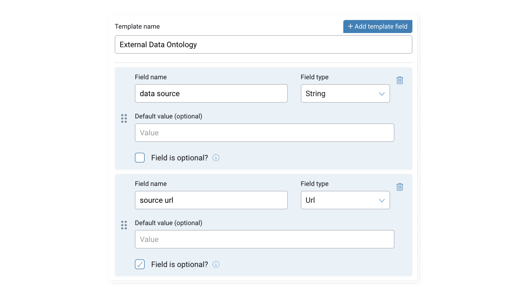 Building custom metadata templates in the ThinkData Works Catalog. These templates can be added to any dataset brought into your data catalog.
Building custom metadata templates in the ThinkData Works Catalog. These templates can be added to any dataset brought into your data catalog.
Secure data flow management and access auditing
This should be a no-brainer, but you might be surprised how many organizations still email spreadsheets from one floor to the next. If you’re sharing open data, you may not have to worry about data security, but if the data is even moderately sensitive (not to mention valuable) you’ll want to make sure you’ve got a way to trace exactly where it’s come from, where it’s going, and who’s using it along the way.
Ensuring the data is delivered through a service with adequate data protection measures is critical, and making sure the delivery is reliable and stable will increase trust.
That covers internal sharing, but what about data sharing between independent organizations?
Historically, if you provide your data to another business unit, it’s a transaction from one black box into another. But if you’re an organization that has limitations on who can use the data, you need to know which users are connecting to the dataset on a go-forward basis. A good data sharing platform should not only let you control the flow of data, but give you insight into how users are connecting to it, and when.
Cloud-native support
Most modern data sharing initiatives are designed for the public cloud exclusively, which not only limits who can leverage them, but also increases spend for provider and consumer as they use more storage to access all the data that’s been shared to them.
The reality is that modernizing companies that are at any stage of becoming data-driven require cloud-native architectures and infrastructure that disrupts their standard operating procedure as little as possible. One of the problems with many sharing solutions and traditional data catalogs is there is a primary migration step to the public cloud that isn’t possible. For organizations with mission critical or sensitive data and transactional workloads, the fine-grained control of an on-premises data centre will always be a necessity.
Even for organizations that would love to do a lift-and-shift to the public cloud, there are miles of legal and practical considerations that grind the process to a halt, just when they’re in the process of trying to modernize. A multinational financial institution can’t take a couple months to physically move their data into the cloud.
No matter the state of your database, you should still be able to safely and securely provide cloud-agnostic access to your data where it resides, without migrating it to a public cloud or creating unnecessary copies.
A mechanism for discovering new data
The rise of the data marketplace indicates a strong need for most organizations to leverage a solution that helps them find and connect to data that resides outside the four walls of their business.
Where data marketplaces often fail, however, is that they provide a shopping experience, not a consumption model. The data marketplace has, historically, been a place that gives users the ability to find data but not a mechanism by which they can then connect to it, which is a bit like letting someone shop for clothes but not let them try anything on.
A new data sharing model has emerged out of this need, and Snowflake made waves last year when they launched the Snowflake Data Marketplace as a place where users could bilaterally share data into each others’ accounts.
This model works well in the public cloud, where it’s relatively easy to create a dataset in a new cloud region, but it’s a bit unwieldy (recreating the data in every cloud region adds substantial overhead to the process) and it can also create runaway costs for compute and storage if you’re not careful.
The ThinkData Works Catalog allows any organization to tap into data consistently, across any variety of sources, and have it delivered in a standard way directly. It offers a range of consumption models. With on-demand data productization, you can easily configure public data assets to an ideal format and schema. Through data virtualization, you can ensure instant and consistent data sharing without raising issues around data warehousing, governance, and security.
Introducing low-migration data sharing
What is needed is a way for organizations to share their data without needing to move it first.
Data virtualization offers a solution here, as it lets users view data from an external warehouse alongside data from other sources without having to move or copy it.
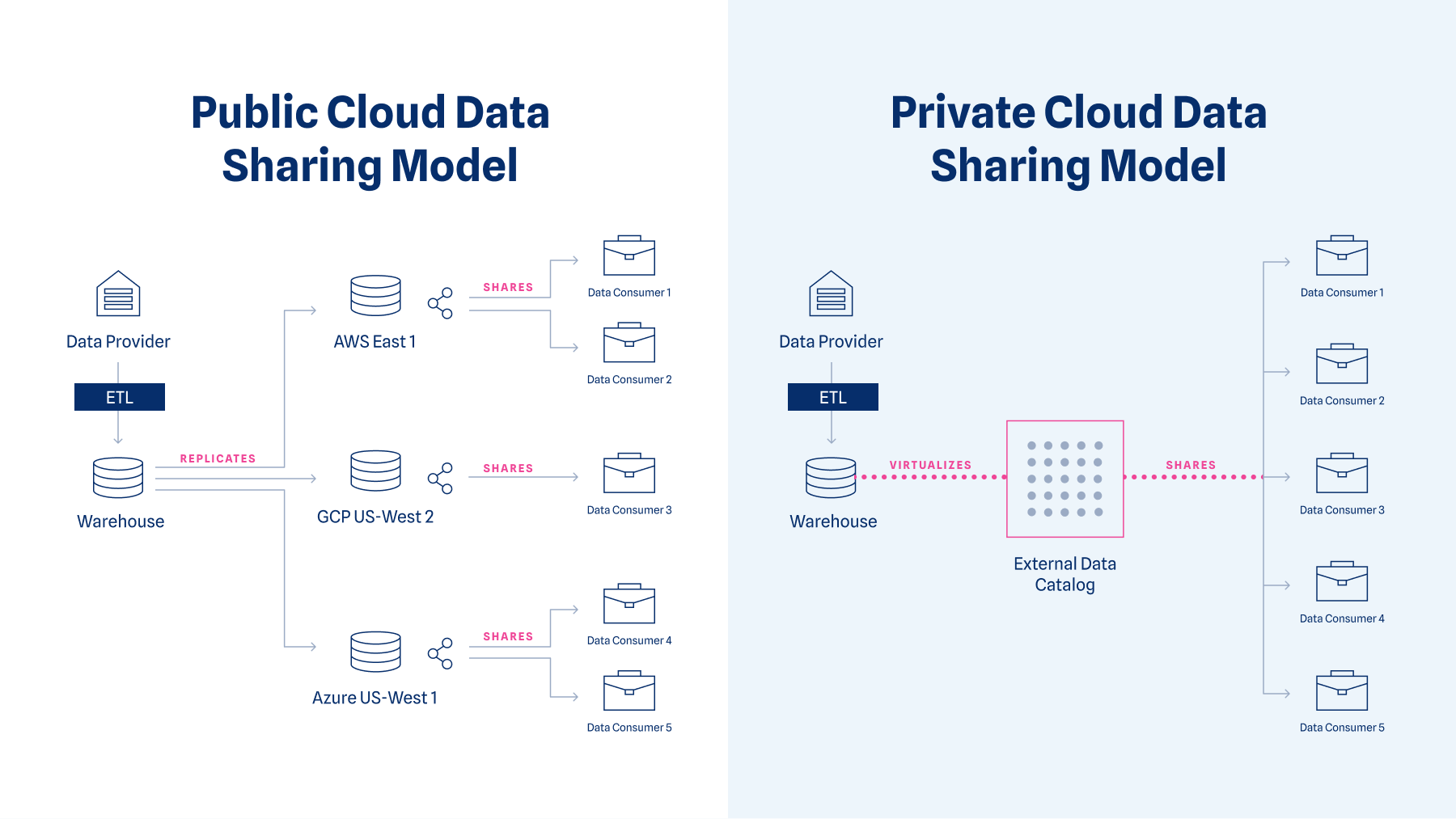
The ThinkData Works Catalog enables virtualization for organizations who want to apply data governance, metadata management, and data sharing onto their data without moving it from where it resides. By fetching data directly from the warehouse and providing it through the platform UI, we let users gain all the benefits of a data catalog without the operational hurdle (and cost) of an extensive migration.
If you're curious to learn more about data sharing, watch our webinar to see how easy it is to distribute data among your teams and individuals. Our platform reaches beyond the traditional discovery and governance that a data catalog offers. By adding data sharing and reporting, the ThinkData Works Catalog unlocks opportunities for collaboration and monetization that were previously impossible.

4 min read
How to better leverage data for risk management and crisis response
It’s becoming increasingly difficult to manage risk in a global climate that’s growing in complexity. On the other side of this coin, however, is an...
3 min read