

4 min read
8 min read
Jonathan Wolf is the Vice President of Partnerships for SafeGraph, a company on a mission to become the definitive source for location data on any physical place around the world.
We were lucky enough to chat with him to get a sense of how place data (and all kinds of external data) are being used, purchased, and thought about, as well as a forward look at trends to come.
Q: Thanks Jonathan for joining us today. Can you explain what SafeGraph does and some of your core responsibilities as the VP of Partnerships?
SafeGraph is a data company that seeks to be the source of truth for all physical places. Our products run the spectrum from CSV files to API endpoints – data that we provide to organizations to improve business outcomes. All the data focuses on what is located where, and visitation trends around those places.
For example, we can tell you that this particular place is a Burger King; we know what a Burger King is, and we know when it opened. We also know information about the volume of people coming and going from that place, and where else they visit, etc.
As the head of Partnerships for SafeGraph, my team and I are responsible for making it easy for our customers to use our data in conjunction with all the other pieces of the solution, whether that's other datasets or other technology or services.
Q: How are organizations using SafeGraph data to enhance their business outcomes?
We like to think of ourselves as a kind of data utility; it's not raw data, it's structured and processed data, which means you can combine it as an ingredient with a lot of other things.
We do a lot of work in retail, hospitality, and real estate. Essentially, people who care about what is located where, and how people are going there, and how that's changing over time. In retail, we see a lot of site selection use cases. This helps the organizations we work with understand not just where I put the next Burger King, for example, but also, if I need to shut another location down, which one? If I want to invest in redesigning the layout of a McDonald's, how do I pick the tester locations? Think of how retail traffic has changed during COVID – companies are looking to make data-driven decisions about how to evolve. 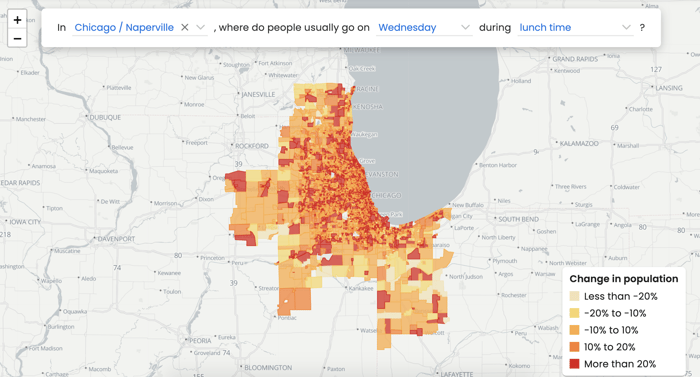
SafeGraph data showing movement patterns on a heatmap
In other industries, our data can be used to answer questions about investment opportunities. This includes questions like “where should I build the next mall?” Or I'm a private equity firm that buys malls, should I buy them all on this side of the street?
There are many different applications for data around what is located where. We spent a lot of time as a company speaking with prospective clients to determine what they’re trying to accomplish so we can provide some ways that SafeGraph data could be useful.
Q: Data, and our consumption of it, has changed a lot in the past few years. One big thing we're seeing right now is a need for companies to trust the data that they're using. How do you inspire trust? How do you make sure that people feel confident about the product they're using?
I think it all boils down to transparency. We think about transparency a few different ways at SafeGraph. We're transparent in terms of how we source our data. We even wrote a blog post not long ago that goes piece by piece on where we source our data and how we know we’re interpreting it correctly.
We also have transparency throughout the entire business. We have very extensive documentation so instead of you having to ask for the definitions of the columns in our data, it's on a public website. Instead of you having to ask, “can I use the data for this use case?” we have a whole section on our doc site that says here are things you should not attempt to do with it.
As is the case with a lot of types of third-party data, there's some sensitivity around the location data we have. We’ve spent a lot of time both working on it, then documenting and evangelizing how we protect user privacy, making sure that data is all permissioned appropriately. We use differential privacy to make sure that it's extremely difficult, if not impossible, to reverse engineer an individual’s footfall pattern in our data.
As a customer of SafeGraph, you can feel very confident about not only what our data is good for, but also, you're not going to find yourself in hot water by utilizing it.
Q: Have you noticed any differences in the way people purchase data over the past few years?
We offer a self-serve data shop where theoretically you could go in there and buy a million dollars’ worth of data. Not surprisingly, people don't do that. But they often buy small pieces of data for an internal skunkworks project to justify a larger budget for things.
We do see a lot of the skunkworks use cases where I'm just one cog in a very large organization. And I know that I'm going to need tens of thousands or hundreds of thousands of dollars to do this at scale. A lot of organizations don't have that budget today. But for $300, I can buy the data I need to be able to build a prototype and build that adoption by making things more tangible.
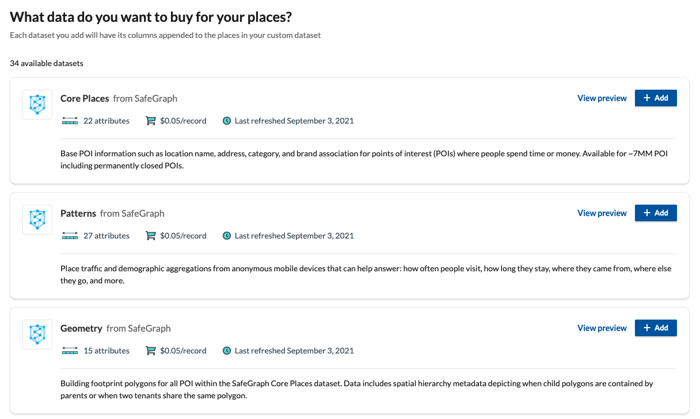
Selecting data from SafeGraph
It’s important that people can go in and gather a small piece of data to work on a skunkworks project. It can be very difficult for individuals at large organizations to justify large data spends if they don't know what the ROI is going to be.
Q: Organizations have been buying data for decades; what’s changed in the last few years that’s disrupted the traditional vendor/purchaser model?
In the past year, I think people's needs have become more rarefied. We saw both that people could not ignore the value of external data and anything that was superfluous got put on the chopping block.
We've seen a spotlight shine very brightly on data like ours. A lot of the decisions that we were talking about earlier – site selection decisions, should I buy this mall or this mall – were made by gut before, and there's always going to be some margin of error when you make decisions that way. When you make decisions this way the margin of error is relatively big, but historically so was the tolerance for that error.
What we've seen in the last year is a much more crystallized recognition of the need for data-driven decisions. And human intelligence is always going to have a role in this. But the idea of solely using intuition or years of experience has been pushed to the back seat because organizations just can't afford to get it wrong anymore.
For example: site selection this past year has been about investments in making the floorplan of retail locations COVID-friendly. We’ve worked with a head of real estate at a retailer who said, “I need to make locations COVID-optimized and it’s going to cost us $25,000 per location.” So, they have to decide: which locations do I open, which locations do I close, do I just leave certain locations closed for now, and which ones do I spend the twenty-five grand on? These decisions are tough to guess by gut. We're seeing a lot of focus now on data, not just like ours but data in general, to make those kinds of decisions.
When I think about what data buying looked like, not two or three years ago but 10 or 15 years ago, there were primarily data co-ops and subjective market research data. In one case you're contributing your data and we're all kind of pooling our data and you get access back to it. In other cases, you're going to hire somebody, who might stand outside of a shop to count how many women walk in and how many men walk in. And that's how you figured out your gender balance for your customers. This is very subjective, highly manual data.
And now there are companies like SafeGraph and ThinkData Works that specialize in providing data and making data available. It's not a by-product; it's the primary reason that we exist. In the case of SafeGraph we provide objective data into the comings and goings of consumers visiting places. In addition to this, there are also transaction datasets and even satellite imagery datasets, all these things that just didn't exist a while ago.
Q: What external data trends do you see emerging over the next few years?
I think we're going to continue to see more data savviness. The huge shortage of data scientists is well documented, and I don't think that shortage is going to change anytime soon. But there are data science programs and university degrees now that didn't exist 20 years ago. So, I think we're currently training the next generation of data scientists. You also see more and more organizations that are starting to think of themselves as data consumers. We need to be thinking about how we can consume that data and why we should consume that data.
I think there's a change in the data buying appetite and mindset. Think of the skunkworks projects I mentioned earlier. We're seeing different ways that people want to consume data and APIs in real time. The SafeGraph dataset is about 8 million rows a month of data. That's a lot. And for any particular use case, you might not need all of it. What you might need are a particular 40 data elements. But you might not even know which 40. So, we're seeing a lot of tools emerging to help pull the right data from the right dataset at the right time. That’s a big change in how organizations consume data.
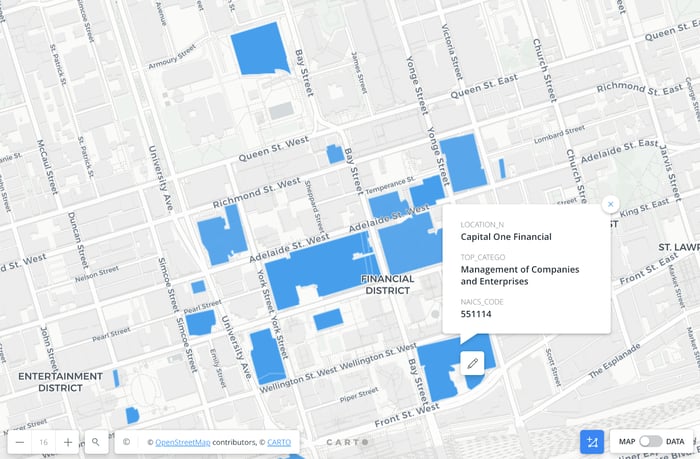
SafeGraph data layers on a map of buildings in downtown Toronto
We're supporting this change as a data provider and building a couple tools of our own, like APIs to let people consume the data that they need at a particular moment. That's a fun challenge for us as a data provider. We’re really good at selling annual subscriptions to big files, but we're also seeing that there's an appetite for different types of consumption, so it means we have to keep up with those things and evolve.
Q: What happened in the past year that has made people rethink their traditional processes?
We've seen a big change in the public sector since the start of COVID. Before the pandemic, we were having conversations with local governments and federal agencies in various countries who were like, “okay, you have data. That's fine.” But they weren’t sold. Why do we need to know if people are going to Burger King or this city park or this cinema?
But the pandemic exposed the problems in the data that historically powered decisions for the public sector. The latency in public data like the census – the information that gives you unemployment statistics, new job creation, etc. – just wasn’t enough to help governments understand how the pandemic was impacting our cities, and it wasn’t granular enough to make decisions off of.
One of the things we did last year was make our data available for free to anybody working on COVID response, like academics and local governments. And we found that a lot of governments realized how interesting the data was when asking questions about how COVID was affecting their communities – not just primary questions, but secondary considerations like equitable access to locations.
Where I’m at, in Denver, the first thing we did was shut down all the parks; but then it actually turned out that being outside in a fairly spread-out place was a great place to be. So, we reopened all the parks, and then this question of equitable access came up. I happen to have a park about 500 meters from my house. Anybody can go to that park, but does anybody go to that park? Or is it just the people who happen to live close by? Getting answers to these sorts of questions help local governments make real decisions about how to manage the crisis and build their cities.
As COVID testing and COVID vaccinations rolled out, we saw that cities can open up a stadium to do mass vaccination, but we don’t all live that close to the stadium. Some people can’t drive there, some of us don’t have jobs that are flexible enough to allow us to get there. So, who actually gets to go get vaccinated?
That’s been a big, big shift that we’ve seen, and it’s led governments to start thinking differently about how they can apply data to their decisions. Outside of COVID, they’re now asking “hey, I have a park that has tennis courts – are people using them?” simple questions that help them intelligently allocate resources.
The shifts that we were talking about for data buyers were happening in the private sector, sure, but we’re seeing the same shift happen in the public sector. That’s really exciting. And I don’t think that’s something that ends with COVID. I think that’s now the new reality of how we make decisions.
Q: One of the tricky things about these possibilities is what we refer to as the Blue Sky Problem: with virtually unlimited amounts of data available to you, how do you choose to start a project?
One of the things that we work really hard on is to try to structure ourselves in a way that's very user-friendly. Let's carve out one use case at a time. So, if you're a large organization, regardless of where you are in the maturity curve, if you say, I want to buy this data set, we spent a lot of time consulting and distilling things down into a clear scope.
The advice that I have for anybody who's struggling in this area as a data provider, or as a data buyer, is start with something bite-size, start with something consumable, get that win and then expand as you go.
We'd like to express our thanks once again to Jonathan Wolf, for sharing his time, knowledge, and thoughts about using data to drive new insights.
Contact us to learn more about how our platform solution can help you get the most out of any data.

4 min read
How to better leverage data for risk management and crisis response
It’s becoming increasingly difficult to manage risk in a global climate that’s growing in complexity. On the other side of this coin, however, is an...
3 min read