

4 min read
3 min read
One of the greatest challenges facing ETL engineers is:
How can we deal with data variety efficiently?
There’s no clear answer, and seemingly no end to the work – every day, new cases need unique handling as the world of available data grows. This is especially true with open data. A variety of machine and manual data entry systems serve opinionated data, gathered over decades through different means, with no standard way to present it.
Using data from anywhere means handling the variety that comes with it – is your organization ready?
Cellular data formats, like .xlsx, are as blank of a canvas as it gets. These formats have no common standard enforced on them, and that causes problems – a defined standard is a prerequisite for automation. Generic ETL solutions provide tools which combine to solve problems case-by-case, but when the goal is to gather and update thousands of datasets per day, it’s impossible to maintain. Can common ETL pipelines handle variety at scale?
Here’s how it might be handled:
A typical ETL
The first step is connecting to sources, each with their own communication methods and nuances. If you’re lucky, your solution has mappers built to connect to the resources these portals provide. Even so, these resources often exist in chaotic and problematic environments. In fact, the average open data network is prohibitively slow, and doesn’t provide random access, a feature that most solutions rely on for performance optimization. Due to this, each file needs to be downloaded before processing.
Handling file types is the first thing solved by any ETL, so even if the datasets are in different formats, the data should be flowing in smoothly. However, problems arise when archives contain multiple file type options for the same dataset. Now, selection needs to be handled for each case so data isn’t brought in twice or lost. If file selection doesn’t go perfectly, there needs to be a method for mistakes to be corrected.
Where are you now?
You’ve now spent hours wrestling with one new source before it’s even usable in your ecosystem. Moreover, we haven’t even discussed headers, footers, guessing column data types, and malformed cells – each of these obstacles is a major time penalty. The advertised performance of the other ETL solution no longer seems very honest.
A typical Atypical ETL
Ingest is ThinkData's solution to the variety problem. It understands how data portals work, and it does so without affecting the output data rate – zero overhead, zero penalty.
Ingest is able to operate faster than industry standards and allows data teams to operate faster, too, even when faced with the variety found in open and public data portals. It understands when archives contain duplicate data, allows for specific file selection within archives, and can easily handle datasets with custom headers, footers, and other artifacts which need special consideration.
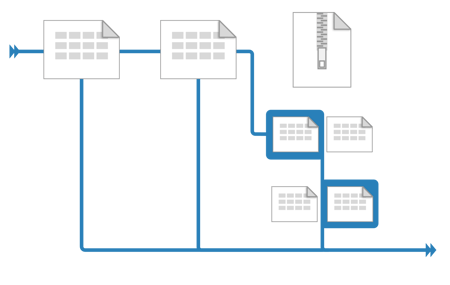
Ingest operates on a streaming download with zero overhead – the data is handled as quickly as it’s served out.
Another boon to your efficiency is that our pipeline doesn’t require a developer to fix the workflow if something goes wrong. Ingest makes manual intervention simple, declarative, and centrally located, and all of these features work together automatically. There’s no costly downtime for every new dataset, and no need for an entire team of people every time you want to bring data into Namara and your organization. What lands in your data warehouse is a polished, ready-to-use product.
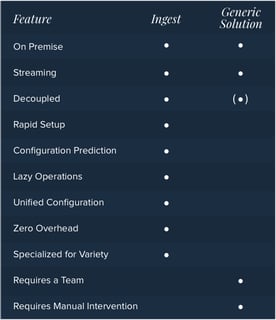
Both solutions are capable of achieving the same end but there are some major differences in the processes:
The generic solution has some appealing features, but requires substantial configuration on every operation, and requires constant management by an experienced team. Ingest, on the other hand, was purpose-built to handle variety, and allows you to tap into data that otherwise wouldn’t make business sense. With the ability to achieve what the generic ETL tool accomplishes and more, Ingest provides workflow benefits that have never before been offered.
The future of Ingest
We’re incredibly proud of where we’ve come, and plenty of companies in the data technology space have taken notice of our progress. Our team is working diligently to expand the capabilities of Ingest with regard to both the variety of data we can handle and the size of the datasets themselves – creating faster, more robust, battle-hardened tools for the enterprise.
Want to learn more about Ingester?
Request a consultation with one of our data experts to learn about how ThinkData’s tech can advance your projects.

4 min read
How to better leverage data for risk management and crisis response
It’s becoming increasingly difficult to manage risk in a global climate that’s growing in complexity. On the other side of this coin, however, is an...
3 min read