

4 min read
5 min read
Based on our roots in open data, transparency is big here. The Namara DevNotes series is a glimpse inside of our tech, bringing the latest updates on our Namara platform. Bronek Szulc is a Software Engineer at ThinkData Works and provides an overview of our latest product feature, Dataspec.
Anyone who has worked with datasets that change over time has felt the pain and frustration when the data or schema updates at the source. Maybe you have relied on a scraped dataset to generate a business report or to feed crucial data into an app, then suddenly one column goes missing, another becomes largely blank, and yet another changes its type entirely.
When a dataset is dynamically updated it can, and often will, change without warning, and in ways that cost time, energy, and ultimately money. Errors are damaging when they are not caught early on by a data maintainer. There is a lot to lose if errors are allowed to surface in an application and affect the integrity of results. Cursing Murphy’s Law, it quickly becomes evident that data products are only as robust as the data that they are built on.
To address this common data quality issue, we developed a new feature on Namara called Dataspec. Dataspec is an in-depth health monitoring dashboard that analyzes data as it's being brought into Namara and provides a variety of metrics and alerts, all generated within seconds. We want to outline what’s included in this new feature, how it can help users gain meta-insight into their data, and how it benefits any team’s DataOps.
Handling data updates at scale
At ThinkData Works, we deal with huge volumes of data coming from thousands of different sources. Hundreds of data sources are created and updated on Namara every hour, requiring constant monitoring of dataset quality at the source level.
Long ago, we recognized that this time-consuming process of bringing data into a system does not leave enough time for data professionals to validate that the data is accurate and properly refined. Even when there is enough time, it is an extremely tedious and error-prone task.
As a result, we implemented a complex data QA workflow. Below are some of the quality checks that the data team used to run every time a dataset updated:
- Data type checks
- Tracking newly added or updated columns
- Upper and lower bound tests, distinct value counts, and null value counts for individual columns
- Aggregate-level checks by comparing a dataset with previous versions
- Tracking the percentage of null cells and dropped columns in order to validate whether they are below an acceptable threshold
- Tracking the missing values in each column by comparing it with a set of pre-listed values or against the previous update
- Tracking invalid or unexpected values in a column
Utilizing these ad hoc queries proved to be helpful for our data team at ThinkData, letting us track possible errors that needed to be handled. But the effort required manual setup and query modification each time a dataset updated. Even when leveraging advanced queries, there was still a need to fully automate the process in order to keep the hundreds of thousands of datasets on Namara at a high standard.
This was the reason we built Dataspec.
Namara Dataspec: get data on data
Dataspec is a dashboard that provides a snapshot of the state of a dataset, captured by key statistical metrics. The simplest way to think about it is that it gives you data about your data – the overall size, shape, health, and structure are all presented in a tidy dashboard for you to understand the data you're working with better.
Since datasets can change constantly, a comparative view of the dataset over time on dimension, column composition, null counts, and schema changes is vital to ensure healthy and predictable output. As such, Dataspec metrics are the first measure that empowers Namara users to hold their datasets to an expected standard.
Meta-metrics
One set of metrics is global, covering broad aspects like column count, row count, percentage row growth and column type counts. Global metrics are graphed as a line chart at the top of the Dataspec dashboard. Beside that is a summary of column differences between the last two dataset versions.
Used together, these offer a historical overview of the dataset that helps answer questions like: how often does the data update? Has the schema changed? Have any columns changed type or position? And more generally, is there any issue with how the dataset is extracted or supplied from its source?
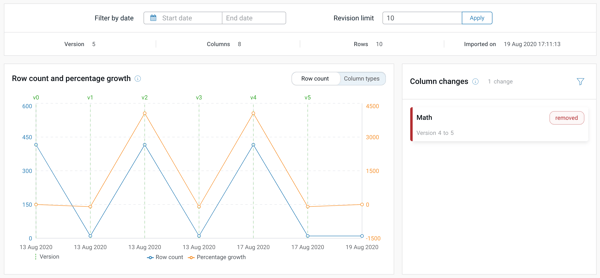
These general metrics are extremely powerful because they provide a broad, at-a-glance check for whether the dimensions of a dataset have changed dramatically, showing the reasons for something like sudden data loss or the addition of new data.
The finer details
The other set of metrics is more specific, covering a detailed analysis of the data within each column. The lower section of the dashboard is a list of columns that display value metrics. These include: minimum; maximum; average; standard deviation; distinct count; and null count.
To complement the raw numbers, there are multiple trend graphs that visualize how a certain column changes across updates – trends like null change, distinct change, and top values by occurrence (the ‘mode’).
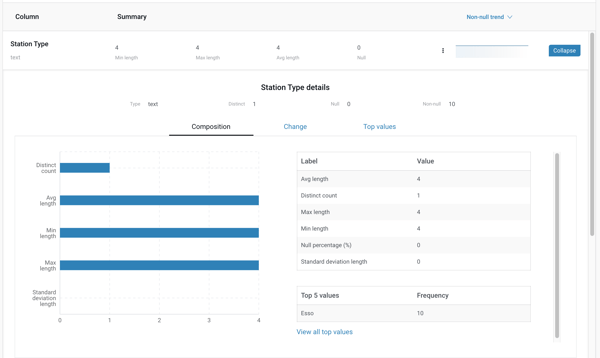
With these specific metrics, a user can track the values of the dataset to ensure that there is no localized loss of data, and that the data is appearing within an acceptable value range. Column metrics can assist in harnessing outlying values and “bad” empty data by helping to answer questions like: how full is my dataset? Are any columns trending towards null? What is the composition of a column? Are distinct values growing in a column across updates?
Using Dataspec, getting down to the column- and cell-level metrics can reveal hidden errors and inconsistencies that may not be found by looking at the data alone.
Macro and micro quality assurance
Dataspec’s second overarching measure is the ability to create tests that the data must pass during updates in order to be deemed healthy. These tests, called ‘alert rules,’ set constraints on properties and aspects of a dataset that are compared against an expected value, which can either be fixed, relative, or query-generated.
Because datasets vary widely and contain different aspects, we’ve built alert rule configuration to be as simple or granular as the user needs. A user can write simple tests that check metric values, or write complex tests against custom SQL-based queries (using NiQL) to satisfy more advanced needs.
Once created, tests run each time a dataset is updated and send notifications via Namara if any tests have failed. This feature of setting up a suite of dataset tests adds extra rigour to the Namara ingestion system’s goal to provide standardized data. A user can write simple tests that check against metric values:
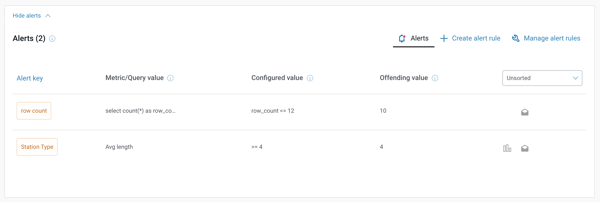
Why is this valuable?
A missing value or an outlier in a dataset might seem insignificant at first. It’s standard practice for analysts and data scientists to ignore or remove outliers before feeding a dataset to their machine learning models or business intelligence reports. However, if the data team doesn't fully tackle the root cause of such errors, then they might eventually end up with significant performance loss, since ML models often rely on the “fullness” and integrity of the data coming from its source over time.
Counting on the source or a third party maintainer to fix errors in the data isn’t best practice, and even in the best case, it’s a waiting game. So the responsibility falls to data teams at the user organization to ensure the quality of each data point, making sure the data is clean and accurate whenever the source is updated. It is a tiring, janitorial exercise in preparing for the unexpected and a balancing act of fine-tuning systems without disrupting their performance.
Dataset health monitoring is one of the responsibilities of a data team; but if it could be automated, it would free up time for data analysts to actually work with the resulting data.
Full confidence in the data you need
Dataspec is the missing piece of the QA puzzle that we now use to monitor the health and shape of data. Now built into Namara, our mission is to share those same benefits with data teams anywhere. This service is engineered to keep out the bad data and alert Namara users of possible issues that threaten their data products.
The metrics generated by Dataspec also make life easier for data professionals by saving them from having to manually load datasets onto their local machines in order to perform basic exploratory data analysis.
Dataspec can save hundreds of hours company-wide, make data teams happier, and most importantly, help maintain the quality of every piece of data flowing through Namara.
Want to learn more about aligning your business and data strategy?
Request a consultation with one of our data experts or browse the largest catalog of solution ready data to determine how ThinkData’s tech can advance your projects.

4 min read
How to better leverage data for risk management and crisis response
It’s becoming increasingly difficult to manage risk in a global climate that’s growing in complexity. On the other side of this coin, however, is an...
3 min read