

4 min read
1 min read
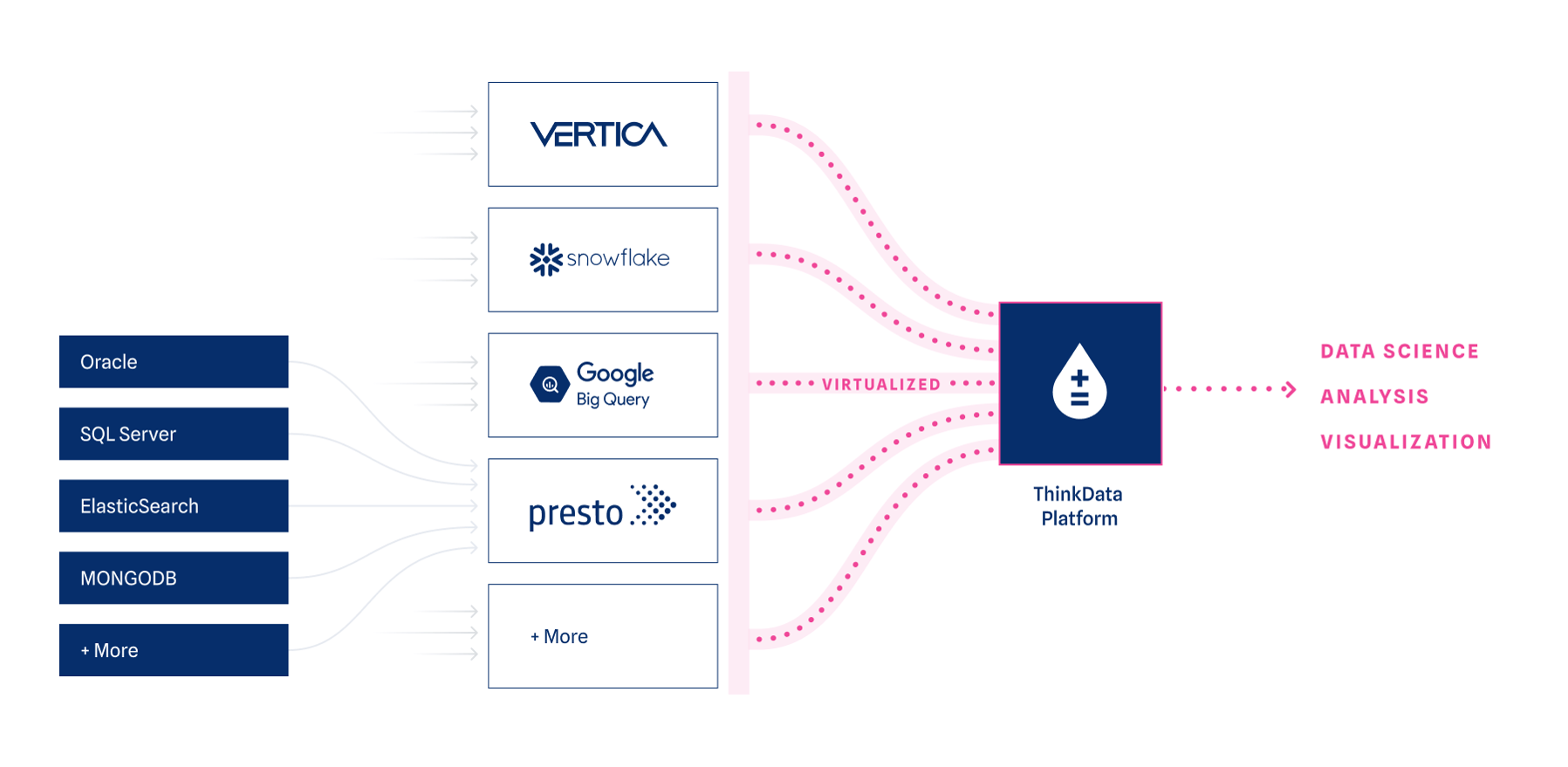
Data virtualization is a complex term for a simple idea: a business should be able to realize the benefits of centralizing data without actually moving that data.
More than just a unified interface for querying data stored in a variety of warehousing solutions, true virtualization allows a business to engage in the higher-level curation, discovery, governance and monetization of their data through a platform which calls that data and projects it back in real time, rather than holding a disconnected copy of it.
Data virtualization creates an abstracted layer over data that enables access and sharing without duplications.
Businesses with a maturing data strategy often invest heavily in warehousing and ETL, streamlining the production, storage, and processing of data across their organization. This is the ideal use case for data virtualization, which brings the many benefits of a data catalog to the table without forcing a rethink or repeat of all of that hard work. Preexisting internal and external data from any source can be transparently cataloged alongside each other, governed and consumed together.
Data virtualization affords several additional benefits which are worth mentioning:
- The rapid onboarding of new data into the catalog, regardless of where it is stored
- Live connectivity, with changes to underlying data visible immediately
- The source data remains the sole source of truth
- Data residency and warehousing architecture remains under full control of the business
Data virtualization is not a new concept, nor is it new to our platform. But today we are excited to reveal a powerful new user interface for the provisioning of virtualized datasets within the ThinkData Catalog Platform!
Months in the making, this new feature allows users of our catalog to easily leverage our virtualization capabilities by intuitively exploring a connected warehouse, selecting relevant tables, and rapidly provisioning datasets in bulk. Having done so, these datasets can immediately be augmented with metadata alerted on, shared, queried, and connected to a variety of industry-leading analysis and visualization tools.
Our team is working hard to support additional data source integrations every day. Interested in learning more about supported integrations, or looking for more information about data virtualization on the ThinkData Catalog Platform? Get in touch for a demo to see how to help you and your team excel with their data.

4 min read
How to better leverage data for risk management and crisis response
It’s becoming increasingly difficult to manage risk in a global climate that’s growing in complexity. On the other side of this coin, however, is an...
3 min read